Xue Yang
Assistant Professor, Ph.D. Supervisor
School of Automation and Intelligent Sensing, Shanghai Jiao Tong University
800 Dongchuan Road, Shanghai, 200240, China
📧 [email protected], [email protected], [email protected]
我正在寻找自驱力较强的攻读硕/博士 (2028年保研、拿到创智/中关村/河套等国家AI学院offer,提前进组实习是必须的,越早越好) 的学生、实习生(长期招收),与严骏驰教授共同指导,目标是在智能体、多模态大模型、空间智能、遥感影像解译等课题上做出有影响力的工作。请随时通过电子邮件与我联系。
Looking for self-motivated students (Master/Ph.D. 2028 spring & fall), interns to join us, co-supervised by Prof. Junchi Yan, with the goal of doing impactful work on the topic of Agentic AI, Multimodal Large Language Model, Spatial Intelligence, Remote Sensing Image Interpretation, etc. Please do not hesitate to contact me via email.
🔑 Research Interests
My research Citations: 13126 interests include Agentic AI, Multimodal Large Language Model, Spatial Intelligence, Remote Sensing Image Interpretation, etc.
2026-06
I will serve as Senior Program Committee for AAAI 2027
2026-06
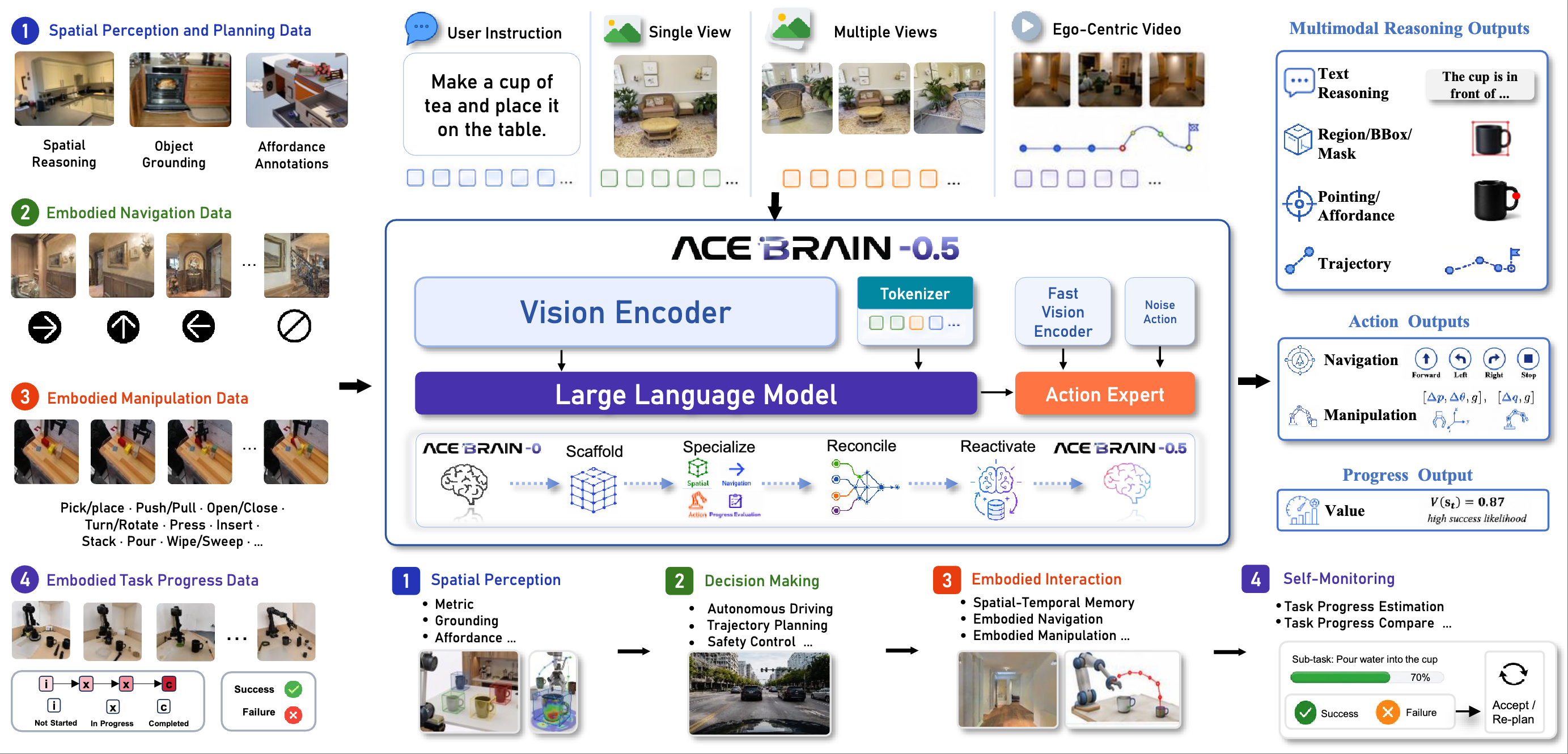
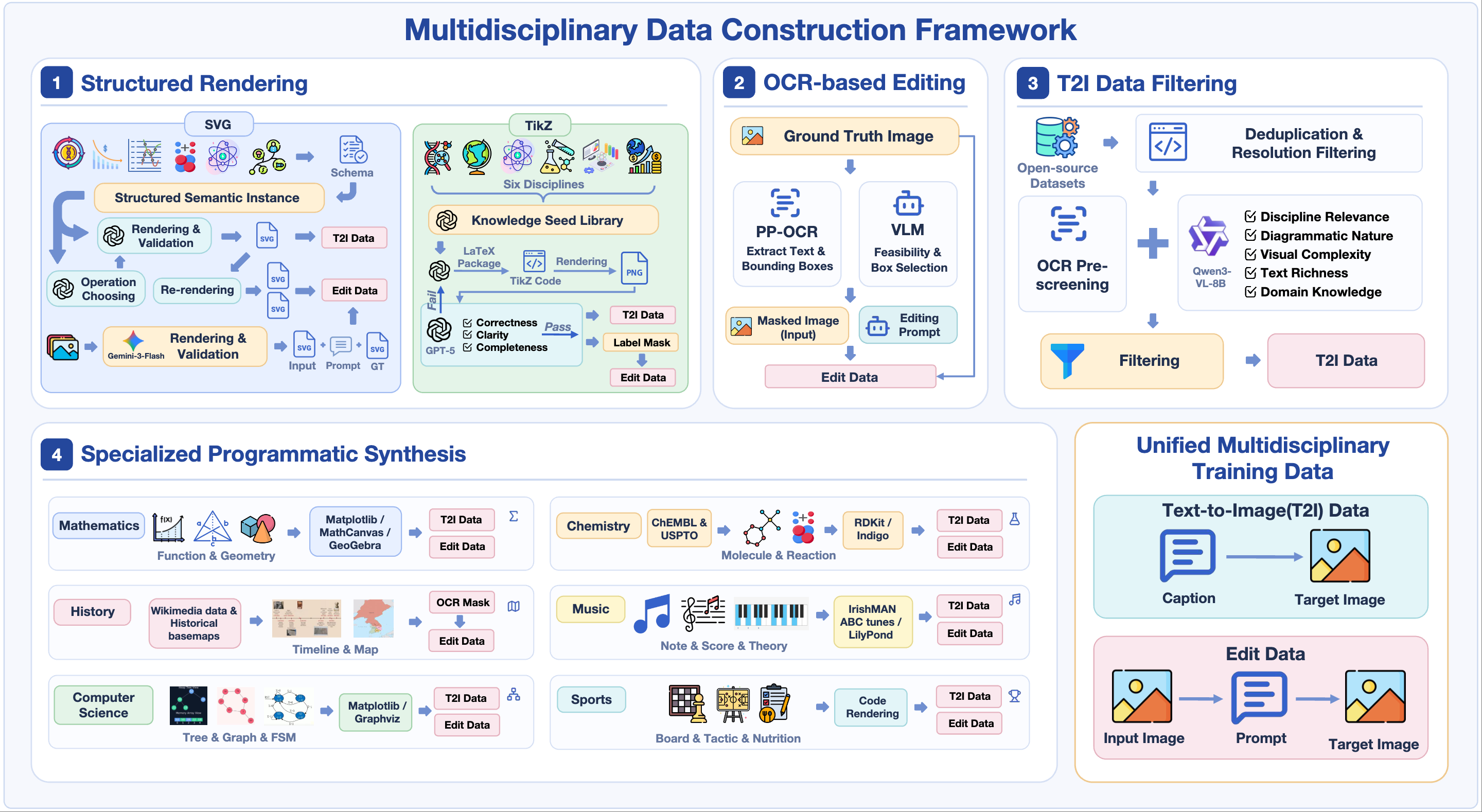
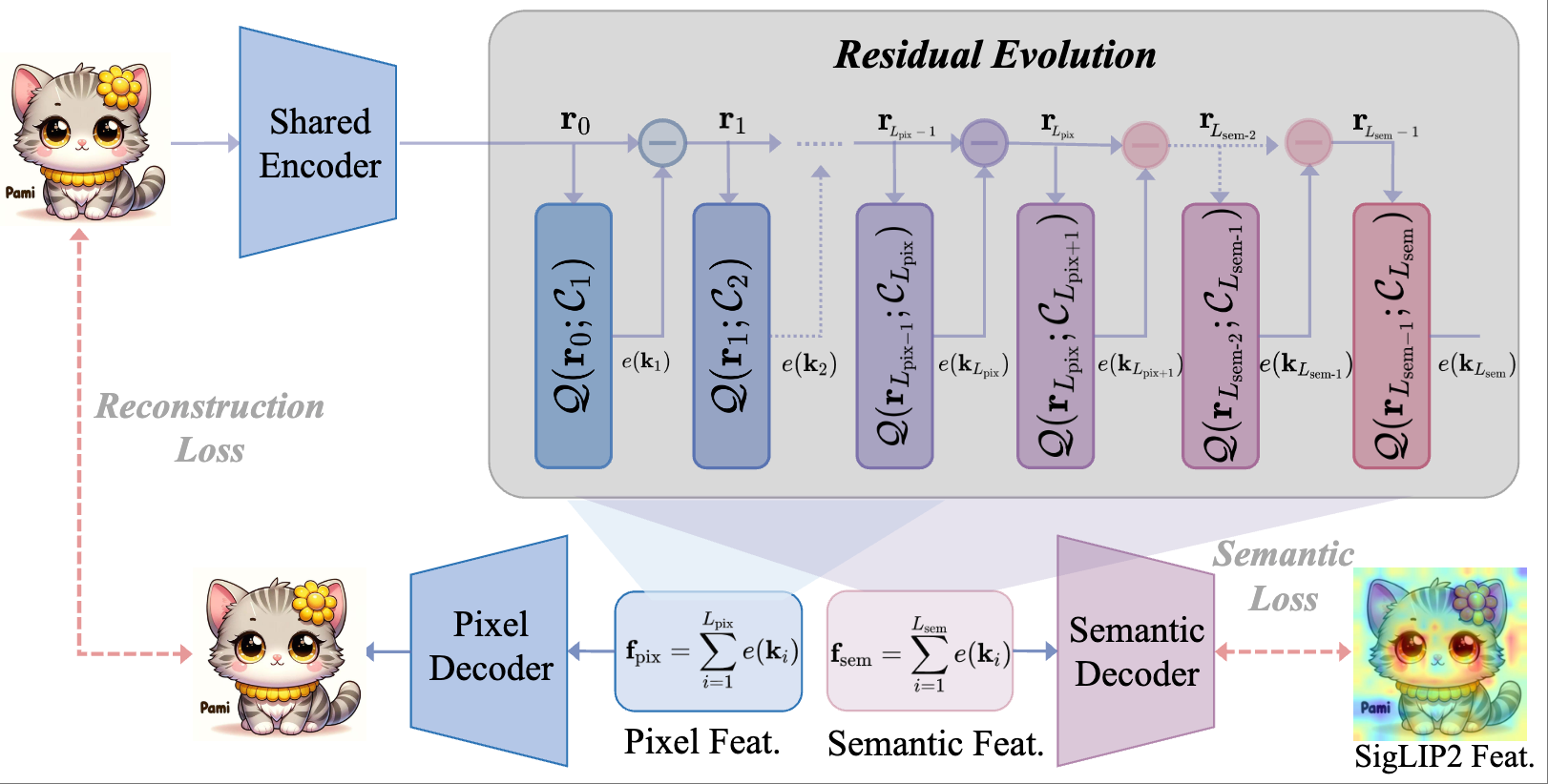
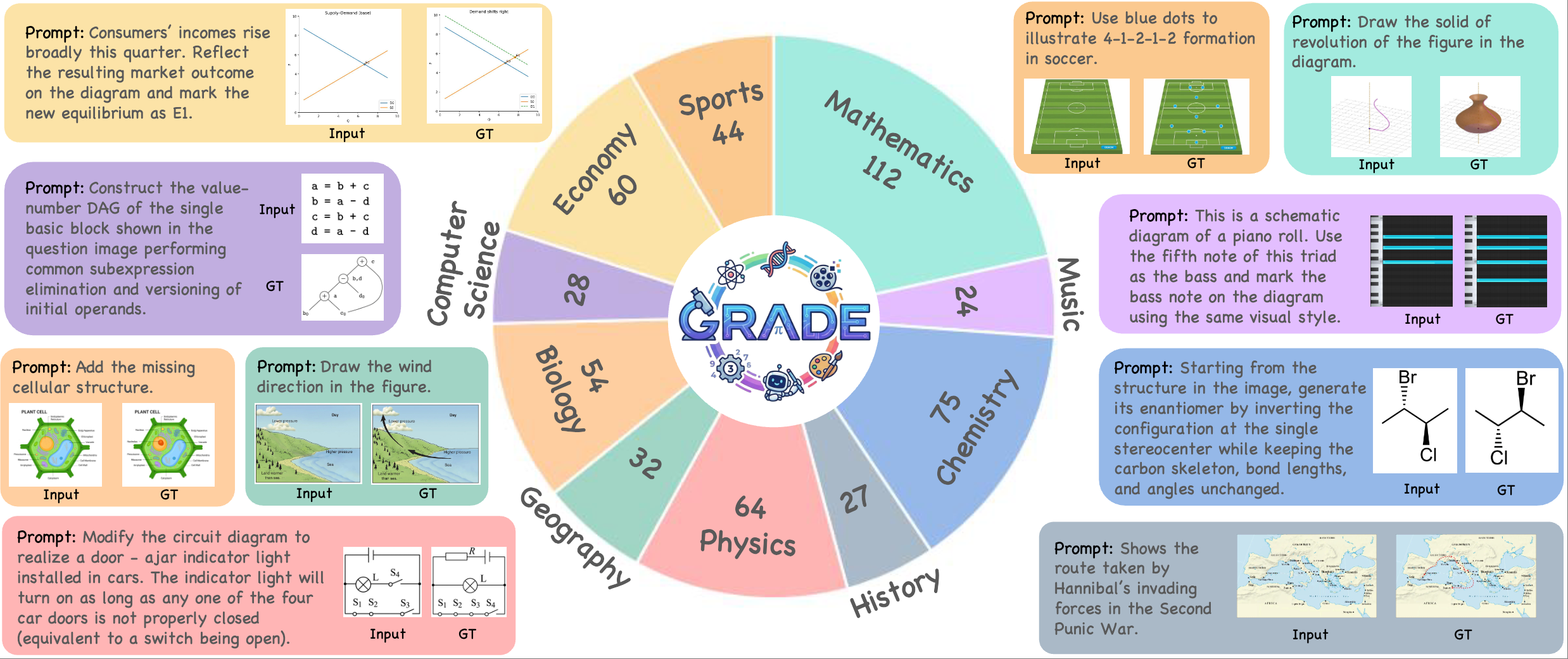
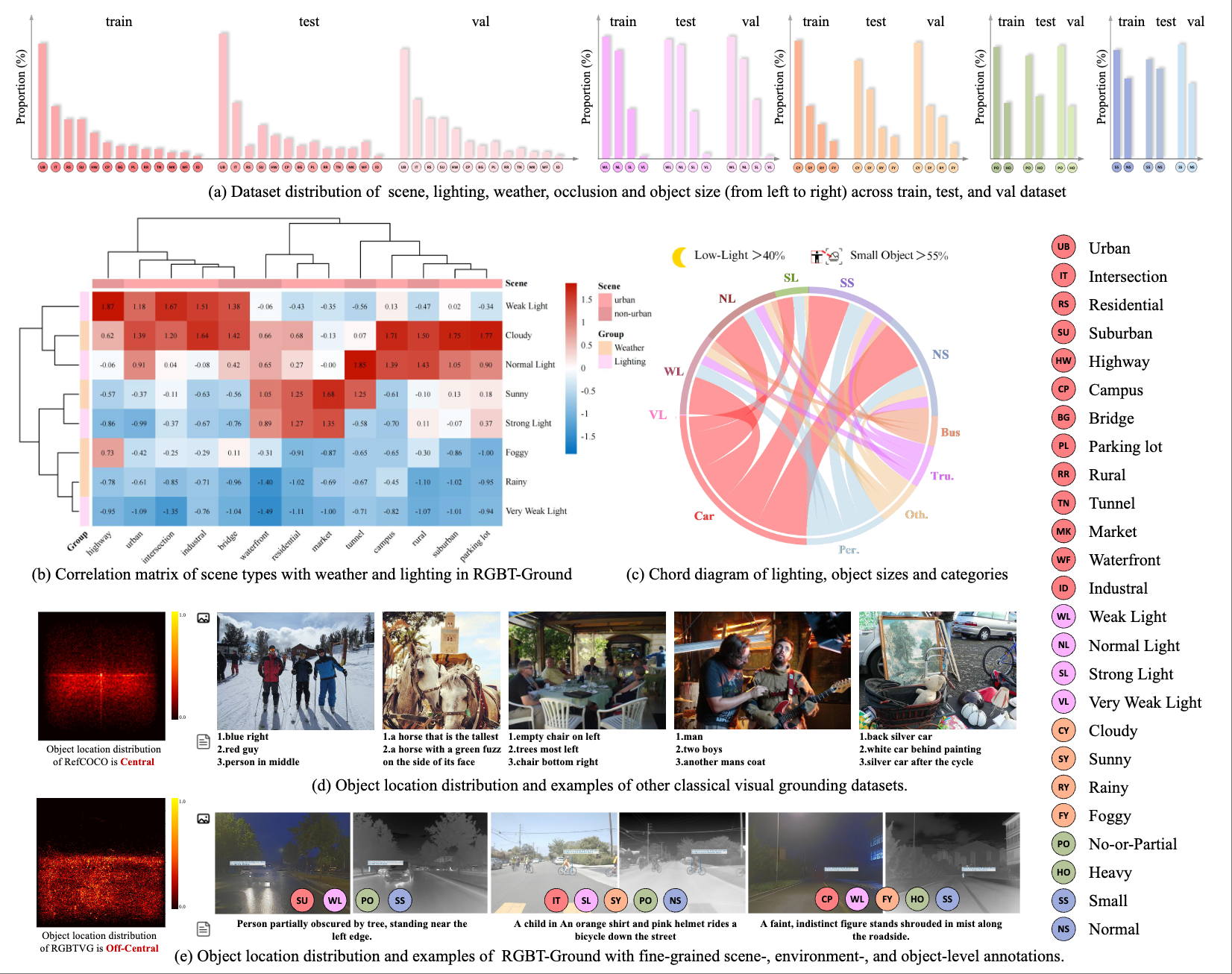
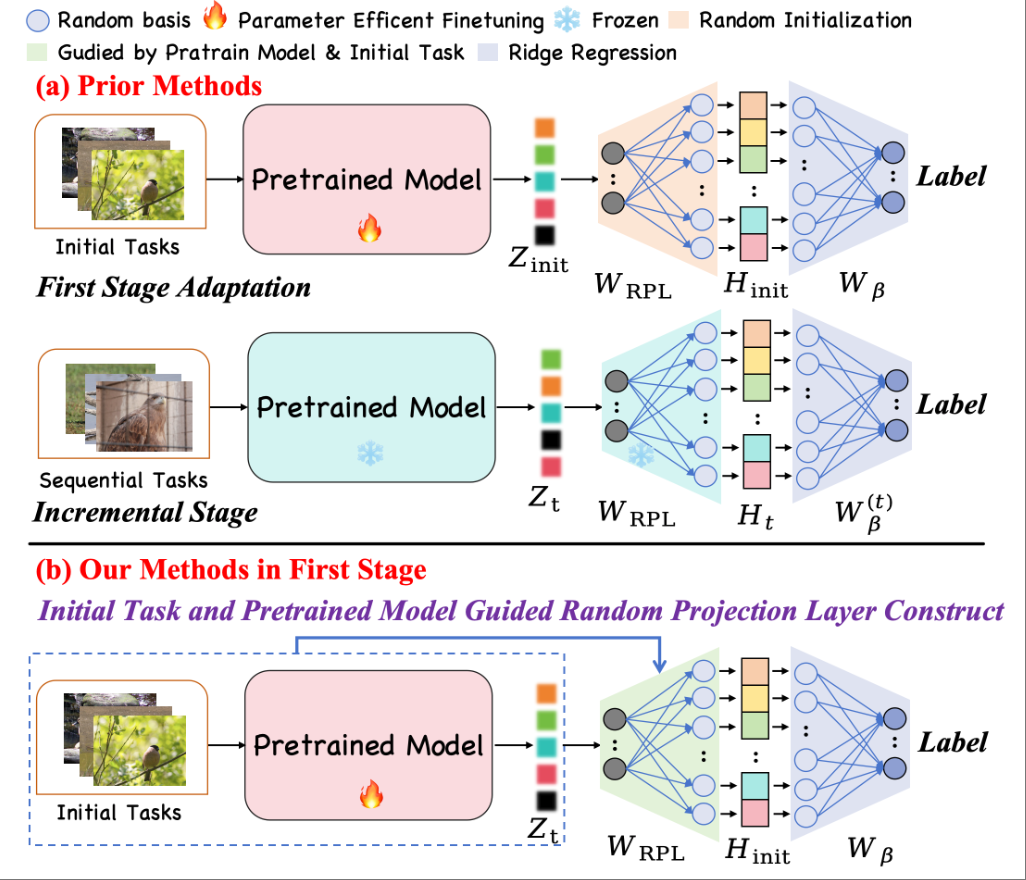
Four papers related to VLM (GRADE, EvoTok), Visual Grounding (RGBT-GroundBench) and Continual Learning (SCL-MGSM) are accepted by ECCV 2026. Congratulations to Mingxin Liu, Ziqian Fan (Sophomore), Zhaokai Wang, Leyao Gu (Sophomore), Zirun Zhu (Sophomore), Yan Li, Ning Liao, Ruilin Li. 🎉🎉🎉
2026-05
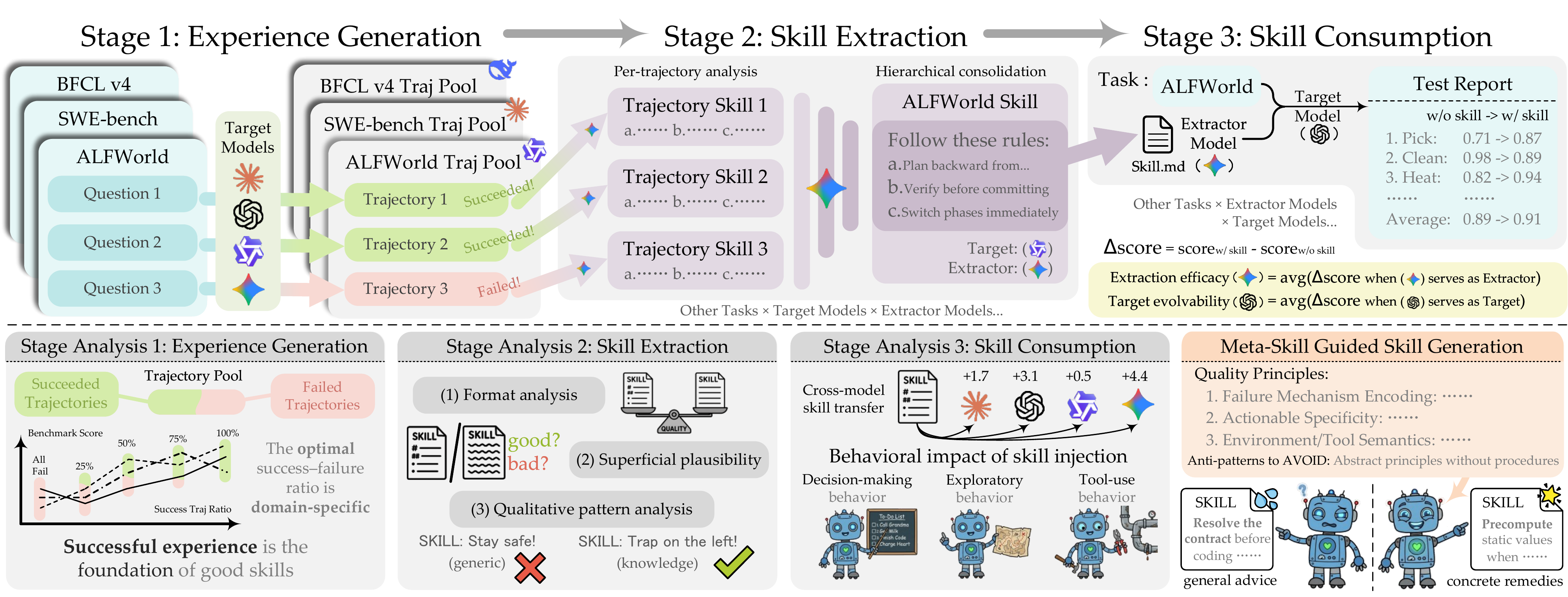
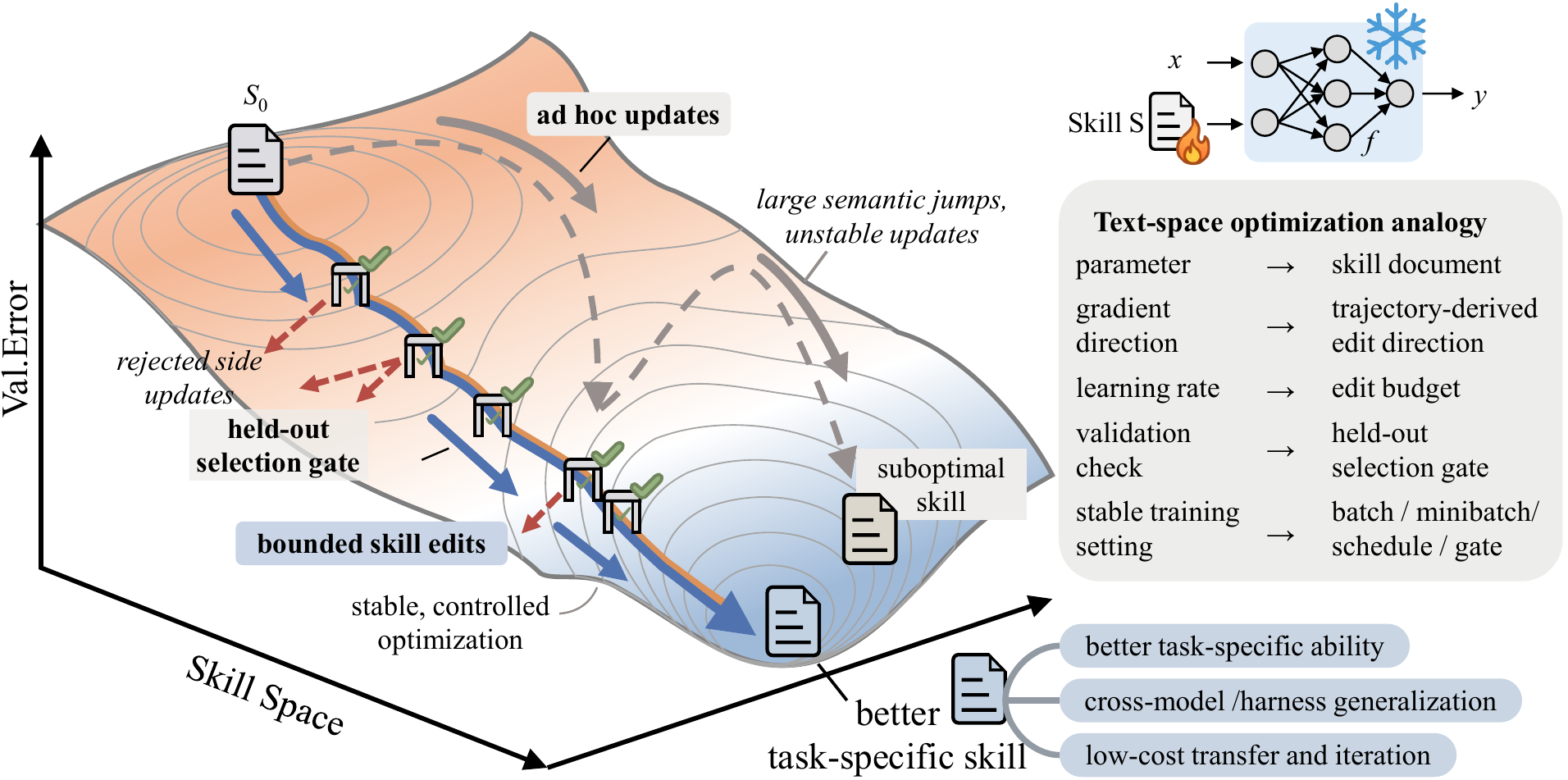
We have open-sourced SkillOpt 
2026-05
Congratulations to doctoral student Ziyang Gong for receiving the first CCF doctoral student funding program. 🧨🧨🧨
2026-05
Serving as the Associate Editor (AE) for Visual Intelligence.
2026-05
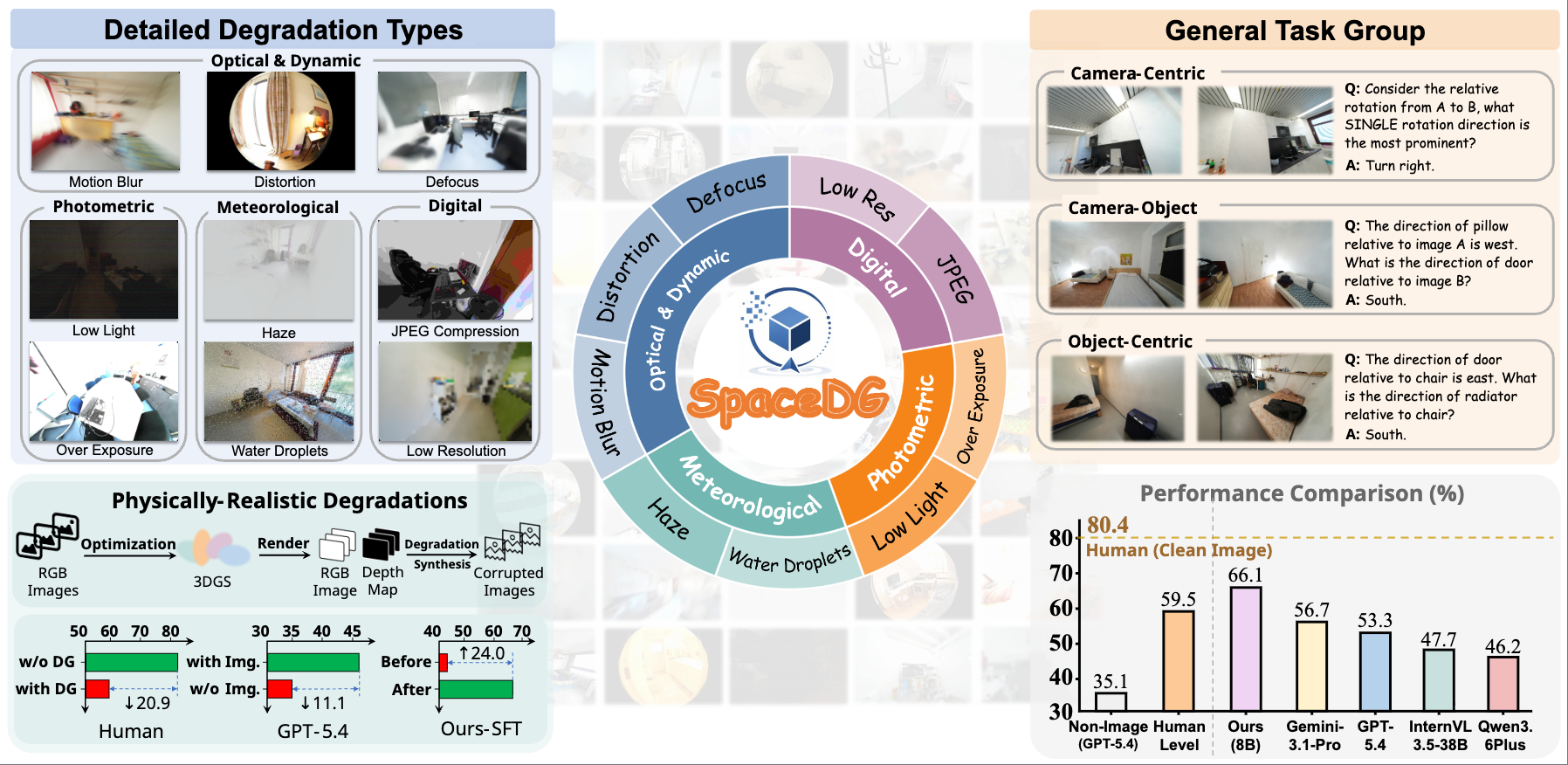
One paper related to Spatial Intelligence (Holi-Spatial, Oral, 168/23918=0.7%) is accepted by ICML 2026. Congratulations to Prof. Zhihang Zhong. 🎉🎉🎉
2026-05
CitationClaw-v2 
2026-05
Serving as the Sponsor Chair for the 4th SCS-CV. 🧨🧨🧨
2026-05
One paper related to RS-VLM survey (GeoChef) is accepted by GRSM. Congratulations to Prof. Yue Zhou. 🧨🧨🧨
2026-05
GeoViS has been selected as a Candidate for the CVPR 2026 Best Paper Award. 🧨🧨🧨
2026-05
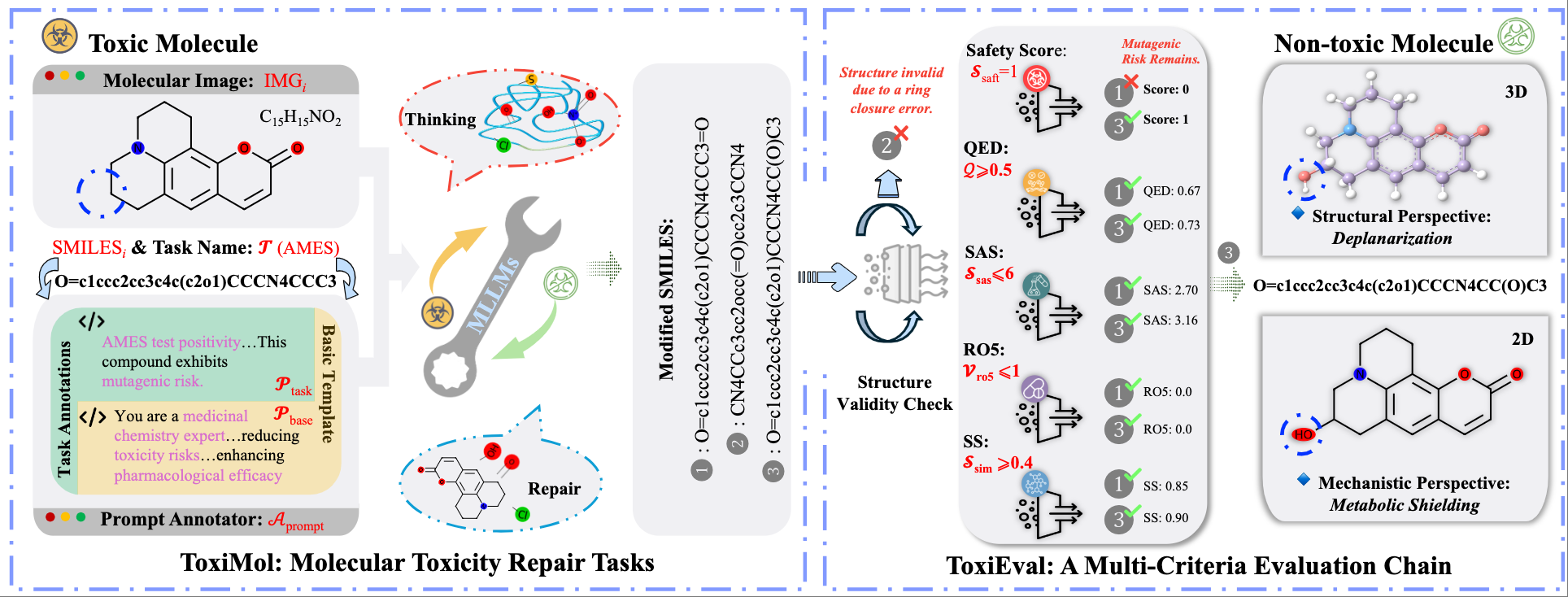
One paper related to AI4SCI (Molecular Detoxification, Oral, 6.1%) is accepted by KDD 2026, AI for Sciences Track. Congratulations to Fei Lin and Ziyang Gong. 🎉🎉🎉
2026-05
Two paper related to Streaming Video (PhoStream) and Spatial Intelligence (Holi-Spatial, Spotlight, 536/23918=2.2%) are accepted by ICML 2026. Congratulations to Xudong Lu and Prof. Zhihang Zhong. 🎉🎉🎉
2026-04
One paper related to object detection in remote sensing images is accepted by TCSVT.
2026-02
Five paper related to Safety of LLMs are accepted by ACL 2026 (two Main Conference, three Findings). Congratulations to Yu Tian. 🎉🎉🎉
2026-03
CitationClaw